Modelling Probability of Loan Default
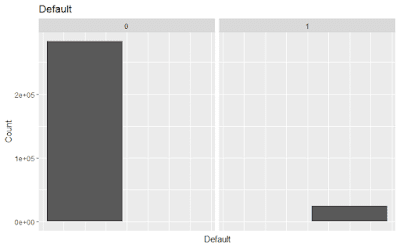
When banks and other financial institutions evaluate a loan request, they must ascertain the risk of default. Defaults can be very costly to banks and predictive analytics can be deployed to help banks make the right decisions. This project involves using a past Kaggle competition to model default of a customer based on many different features. Data Exploration The dataset comprises over 300,000 customers with over 100 features; it is quite a large dataset packed with data. Let's try to make sense of it. It gives demographic and financial information of a customer and then says if he/she defaulted on a loan. Let's first get a broad-level overview of the fraction of defaults. The bank issues both cash loans and revolving loans. The latter are flexible loans and are rather open-ended. Let us see how default rates vary based on the type of loan. It seems that a smaller proportion of revolving loans,...
