Predicting Customer Conversion: A Data-Driven Approach
The following blog post reflects the efforts of my team - Daria Herasymova, Hirak Bhayani, and I - during Duke University's Datathon competition.
As Business Analytics graduate students of Duke University’s Fuqua School of Business,
we have a plethora of resources to explore & have access to many opportunities to build
our data science skills and experience. We were excited to put to good use all that we
learned in our classroom sessions conducted by Prof. Alex Belloni at an annual datathon
that took place on campus. Organized by Duke Machine Learning, the Duke Datathon was
a weekend-long event where teams solved an existent business challenge faced by a
marketing technology & consumer engagement company that works with over 60,000
brands across a wide array of industries. The firm predicts customer churn by examining
content across 80 billion web pages each day and deriving meaning from words and
sentences to determine likely purchase intent through page-level analysis thereby enabling a deep
understanding of the shopper’s browsing behavior across 1400 interest topics.
our data science skills and experience. We were excited to put to good use all that we
learned in our classroom sessions conducted by Prof. Alex Belloni at an annual datathon
that took place on campus. Organized by Duke Machine Learning, the Duke Datathon was
a weekend-long event where teams solved an existent business challenge faced by a
marketing technology & consumer engagement company that works with over 60,000
brands across a wide array of industries. The firm predicts customer churn by examining
content across 80 billion web pages each day and deriving meaning from words and
sentences to determine likely purchase intent through page-level analysis thereby enabling a deep
understanding of the shopper’s browsing behavior across 1400 interest topics.
Team Members: Daria Herasymova, Hirak Bhayani, and Ansh Jain.
Time allocated: 12 hours
Goal: The challenge presented to the teams was to “attack the dataset and come up with the analysis
and visualization while racing against the clock.”
and visualization while racing against the clock.”
Business Understanding
The increase in computational power and the availability of a variety of data had a tremendous
impact on the application of digital marketing. The technology allows us to collect digital data to
better understand the customer and tailor business solutions to better meet customers’ needs. A
“conversion” essentially refers to an event where an online browser clicks on an ad and goes on to
perform a key tangible action such as signing-up or registering or making a purchase. The goal of the
company is to eventually invest their limited marketing dollars in ad campaigns that optimize
spend (Return on Advertising Spend - ROAS) in a way that customer acquisition is maximized.
impact on the application of digital marketing. The technology allows us to collect digital data to
better understand the customer and tailor business solutions to better meet customers’ needs. A
“conversion” essentially refers to an event where an online browser clicks on an ad and goes on to
perform a key tangible action such as signing-up or registering or making a purchase. The goal of the
company is to eventually invest their limited marketing dollars in ad campaigns that optimize
spend (Return on Advertising Spend - ROAS) in a way that customer acquisition is maximized.
About the dataset
We were given 3 files - a training set, a validation set & a file on topics of interest. The training data
records user interest of 8456 users in 1497 topics, which fall into 25 categories, such as ‘arts and
entertainment’, ‘books and literature’ and so on. The interest levels are recorded based on the user’s
online activity and are numbers between 0 and 1, where a higher number indicates greater interest.
There are two metrics of interest: long-term interest and short-term interest. The variable of interest is
a binary variable which records if the customer converted or not; the meaning of conversion is vague
in this case and refers to anything from clicking a link, subscribing, or purchase, depending on the
business’ goals. The data provides no distinction among the various categories of conversion.
Our task is to train a model which will be used to predict the probability of conversion for a user
given interest levels in the various categories and validate the model using the given validation data.
records user interest of 8456 users in 1497 topics, which fall into 25 categories, such as ‘arts and
entertainment’, ‘books and literature’ and so on. The interest levels are recorded based on the user’s
online activity and are numbers between 0 and 1, where a higher number indicates greater interest.
There are two metrics of interest: long-term interest and short-term interest. The variable of interest is
a binary variable which records if the customer converted or not; the meaning of conversion is vague
in this case and refers to anything from clicking a link, subscribing, or purchase, depending on the
business’ goals. The data provides no distinction among the various categories of conversion.
Our task is to train a model which will be used to predict the probability of conversion for a user
given interest levels in the various categories and validate the model using the given validation data.
Variables observed across these files are as follows:
Topic_id: Numerical identifier of the topic
Topic_name: Topic of interest
userID: Identifier for each user (Unique for this dataset)
inAudience: This column represents whether or not the shopper has converted in the past.
A TRUE suggests that the shopper has converted & FALSE suggests that the shopper has not
converted
A TRUE suggests that the shopper has converted & FALSE suggests that the shopper has not
converted
ltiFeatures: Long Term Interests. This value represents the proportional interest the user has in
that topic.
that topic.
stiFeatures: Short Term Interests. This value represents the same as above, however, for the
proportional short term interest the user has in a particular topic.
proportional short term interest the user has in a particular topic.
Data Exploration
The first step of our analysis is exploration through visualization that guides the rest of the analysis,
as it allows for better data understanding and the ability to generate interesting insights. During
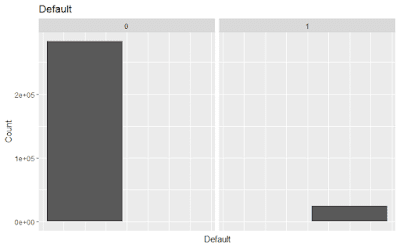
that phase, we have realized that the data is unbalanced: there are over 850K records of customers
that did not convert and only 166K of customers that converted. This presents a challenge that we
would try to solve during the data preparation phase.
as it allows for better data understanding and the ability to generate interesting insights. During
that phase, we have realized that the data is unbalanced: there are over 850K records of customers
that did not convert and only 166K of customers that converted. This presents a challenge that we
would try to solve during the data preparation phase.
In Figure 1, we explored the number of records by topic. As you can see, the most popular topic is
Arts & Entertainment, over 170K people have Arts & Entertainment among their interest, which
is twice as much as the second-runner - Food & Drinks. That provides us an understanding of the
broader topics that are currently of great interest to the public.
Arts & Entertainment, over 170K people have Arts & Entertainment among their interest, which
is twice as much as the second-runner - Food & Drinks. That provides us an understanding of the
broader topics that are currently of great interest to the public.
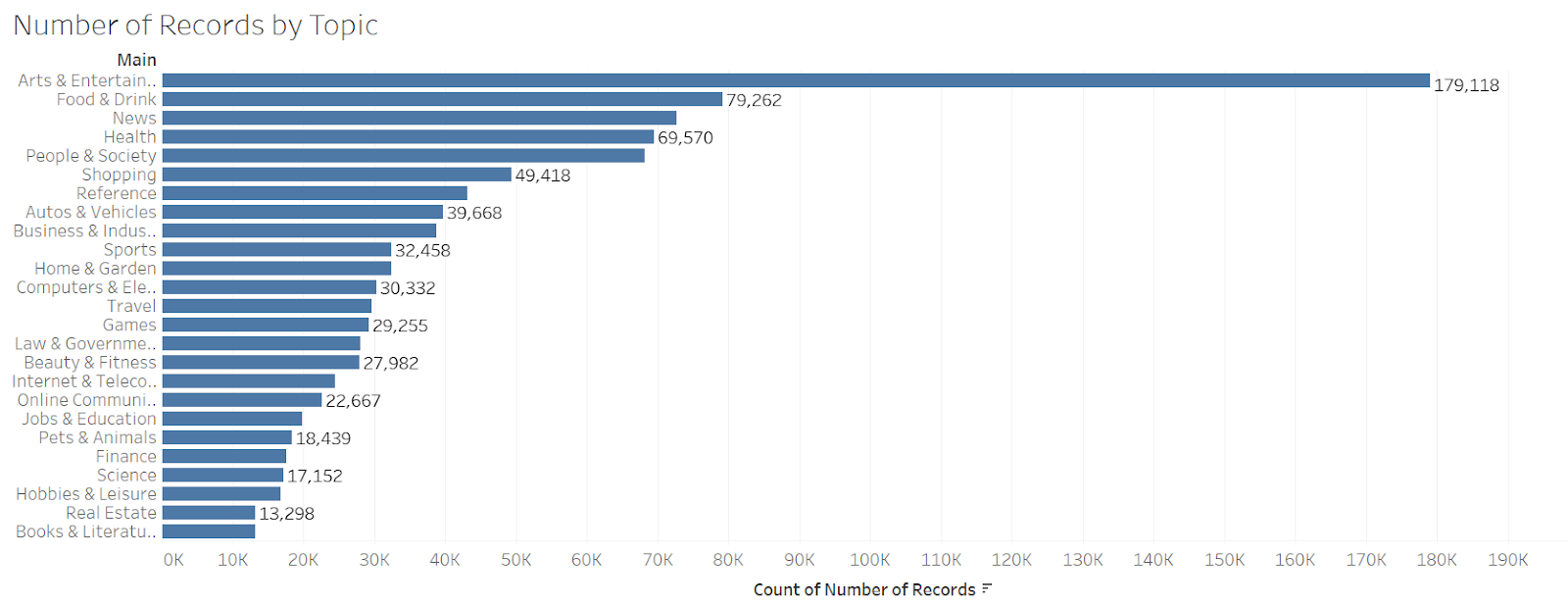
Figure 1. The number of records by topic
The high number of records indicate that the topic is among the topics of interest of the highest
number of users but the interest in the topic may vary. Thus, to dive deeper, the main topics that
users display the highest interest were identified (Figure 2.) According to our analysis, the users,
on average, show the highest interest in the News and Games, followed by Arts&Entertainment.
The average of long-term interest across the topics is 0.0116.
number of users but the interest in the topic may vary. Thus, to dive deeper, the main topics that
users display the highest interest were identified (Figure 2.) According to our analysis, the users,
on average, show the highest interest in the News and Games, followed by Arts&Entertainment.
The average of long-term interest across the topics is 0.0116.

Figure 2. Long-term Interest by topic

Figure 3. Average of Long-term Interest by Category
The focus of our analysis is to be able to predict whether the individual will convert based on the
digital footprint, that is quantified by the expressed level of interest by the topic. To establish the
connection between the long-term interest and the conversion rate, we compared the distribution
of long-term interest for customers who converted compared to customers that did not convert.
Figure 3 illustrates that the average long-term interest interest by topic is higher for individuals
who have indeed converted, indicating a possible positive correlation. Interestingly, News are
outliers for both groups, corroborating the insights generated in Figure 2: the public has a very
high long-term interest in News.
Finally, the conversion rates by topic, calculated by the number of users who converted
divided by the total number of users interested in the topic, were compared. Figure 4
illustrates that the highest conversion rate of 32.5% is exhibited by Autos & Vehicles,
followed by the Real Estate. The businesses in those industries may benefit the most
by purchasing online advertising. The average conversion rate across the topics is 17.85%.
The size of the circle illustrates the long-term interest by topic. It is worth noting that higher
long-term interest doesn’t necessarily indicate higher conversion rate.
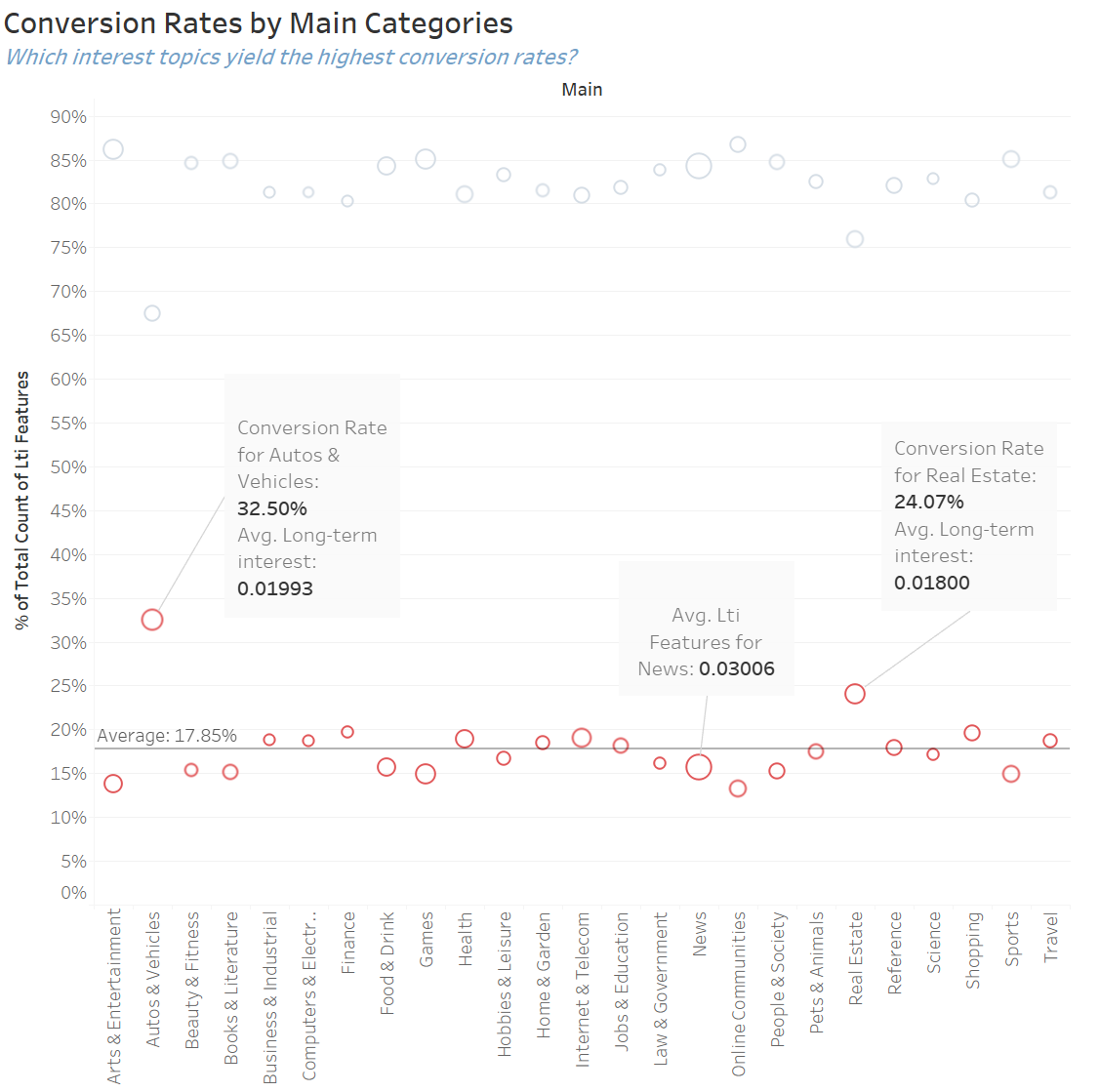
Figure 4. Conversion Rates by Main Categories
The data visualization allowed us to better understand the data we are working with and
The data visualization allowed us to better understand the data we are working with and
define the next steps for our project to reach the stated goal.Specifically, to develop a model
that accurately predicts the conversion variable based on interest variables by the topic. To
proceed, the next step is data cleaning.
Data Processing
The data is very long to begin with. Each user has as many rows as there are topics for which interest
levels are recorded for the user. Below are the first 12 rows of the data:
levels are recorded for the user. Below are the first 12 rows of the data:

We identify many discrepancies in the short-term interest level, for example, for each user, all
short-term interest levels must add to 1. However, that is clearly not the case in our data. Besides,
short-term interest values are missing for many users. We decide to delete this column and focus
simply on the long-term interest values. Moreover, as there are 1497 topics for which users have
logged an interest level, we have to simplify the data into the 25 categories as it is not feasible
for us to include nearly 1500 features in our model.
short-term interest levels must add to 1. However, that is clearly not the case in our data. Besides,
short-term interest values are missing for many users. We decide to delete this column and focus
simply on the long-term interest values. Moreover, as there are 1497 topics for which users have
logged an interest level, we have to simplify the data into the 25 categories as it is not feasible
for us to include nearly 1500 features in our model.
Another sheet includes the master topics to which each of the topics belong. After merging the two
dataframes, we now have the interest levels for each user in particular topics and the master topics.
As a user often has a logged interest level for many topics within a master topics, we aggregate the
data where the interest level in a master topic is now the sum of all the interest levels in the
corresponding topics.
dataframes, we now have the interest levels for each user in particular topics and the master topics.
As a user often has a logged interest level for many topics within a master topics, we aggregate the
data where the interest level in a master topic is now the sum of all the interest levels in the
corresponding topics.
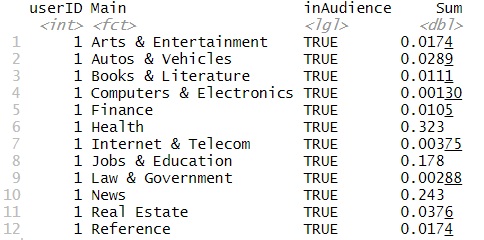
Since each topic is a feature which we will use in our models, we spread the data so each topic is a
separate column.
separate column.
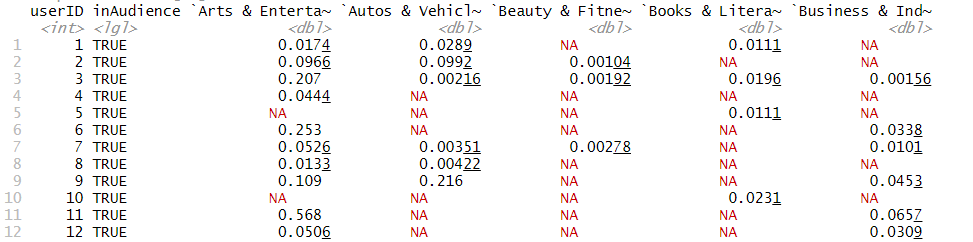
Our data contains many NA values. We assume that these are instances where a user has no recorded
interest in a particular category. We therefore impute all NAs to 0. A final data cleaning step involves
renaming column names to strings without spaces and special characters just to make analysis easier.
interest in a particular category. We therefore impute all NAs to 0. A final data cleaning step involves
renaming column names to strings without spaces and special characters just to make analysis easier.
Balancing
The data is highly imbalanced; among the 8456 users, only 1465 (17.3%) have converted. We
therefore perform undersampling and oversampling on the data to create a balanced random set
which will allow us to run machine learning algorithms on the data. The balanced data contains
8456 observations, of which 4266 did not convert and 4190 did convert; through oversampling,
we have created synthetic data of the minority class based on the features available.
therefore perform undersampling and oversampling on the data to create a balanced random set
which will allow us to run machine learning algorithms on the data. The balanced data contains
8456 observations, of which 4266 did not convert and 4190 did convert; through oversampling,
we have created synthetic data of the minority class based on the features available.
Modelling
All the following models were run on the balanced data.
Logistic Regression
As identified earlier, the objective of our modelling is classification. Specifically, using customer’s
long-term interest in various topics to predict whether one will convert. The first step of modelling
was to utilize the logistic regression to achieve our objective. Logistic regression is often the
simplest and most interpretable out of predictive models, but often is not the most accurate
when dealing with unbalanced data.
long-term interest in various topics to predict whether one will convert. The first step of modelling
was to utilize the logistic regression to achieve our objective. Logistic regression is often the
simplest and most interpretable out of predictive models, but often is not the most accurate
when dealing with unbalanced data.
The final logistic regression is as follows:
InAudience = -0.25572 - 1.02549*Arts - 4.93336*Autos - 2.16796*Beauty -3.45708*Books
(0.04691) (0.14346) (0.30073) (0.76392) (1.15127)
+1.14066*Health +1.74384*Home +1.96273*Internet +2.33819*Jobs
(0.23794) (0.63067) (0.36101) (0.70098)
+0.70053*People +2.88936*Pets +2.15380*Real Estate +1.33981*Shopping
(0.34677) (0.73394) (0.45669) (0.39041)
The interesting takeaways from the above model:
The Autos category has the highest loading, meaning that, among other interests, the
interest in autos is most positively correlated with the conversion of the customer. This insight is
also confirmed by other models used.
The Arts, Beauty and Books categories have a negative statistically significant correlation with
the conversion rate. The users that have high interest in those categories may be less likely to convert.
The Autos category has the highest loading, meaning that, among other interests, the
interest in autos is most positively correlated with the conversion of the customer. This insight is
also confirmed by other models used.
The Arts, Beauty and Books categories have a negative statistically significant correlation with
the conversion rate. The users that have high interest in those categories may be less likely to convert.
Classification Tree
Further, we ran a classification tree using all our category interest ratings as features. Interestingly,
it appears that the interest in autos and vehicles alone helps predict whether a user converted.
it appears that the interest in autos and vehicles alone helps predict whether a user converted.

Interest in autos and vehicles is a significantly important variable and it trumps any other
variable. However, this is not enough of an analysis and so we chose to explore other algorithms.
variable. However, this is not enough of an analysis and so we chose to explore other algorithms.
Random forest
We then ran a random forest with 500 trees. While interest in autos was still the most important
variable, the difference was not so stark and many other variables came out as important as well.
The model had an error rate of just above 10%.
variable, the difference was not so stark and many other variables came out as important as well.
The model had an error rate of just above 10%.
The precision of the model is 92.4%; among all the users the model predicted would convert, 87% of
the users actually converted. The recall of the model is 85.9%; among all the users that actually did
convert, the model identified 85.9% of them.
the users actually converted. The recall of the model is 85.9%; among all the users that actually did
convert, the model identified 85.9% of them.
Support Vector Machine (SVM)
Since the data is supervised & the task to be performed is classification, we also ran the SVM
algorithm on the balanced data. Using the labeled training data, the SVM algorithm outputs an optimal
hyperplane which categorizes the data. To learn more about the hyperplane, the problem at hand is
transformed using linear algebra & this is where the kernel is useful. We have used a linear kernel.
algorithm on the balanced data. Using the labeled training data, the SVM algorithm outputs an optimal
hyperplane which categorizes the data. To learn more about the hyperplane, the problem at hand is
transformed using linear algebra & this is where the kernel is useful. We have used a linear kernel.
Validation
We cleaned and prepared the validation data just as we did the training data and then validated
the random forest model first. The validation is a highly imbalanced dataset and it would be
interesting to see how our models from the balanced training data perform on the validation data.
the random forest model first. The validation is a highly imbalanced dataset and it would be
interesting to see how our models from the balanced training data perform on the validation data.
Logistic Regression
The model yields over 99 percent in accuracy, but since we are working with unbalanced data, it
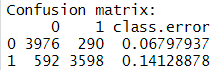
was important to consider other measures of performance. The confusion matrix is presented below:
was important to consider other measures of performance. The confusion matrix is presented below:
The true positive rate, known also as recall, is 0.02278 and precision is only 0.25. Thus, the model
has a poor performance out-of-sample. Our next step was to use more sophisticated models, such as:
classification tree, random forest, SVM and XGBoost.
has a poor performance out-of-sample. Our next step was to use more sophisticated models, such as:
classification tree, random forest, SVM and XGBoost.
Random Forest
The precision of the random forest is 14% while the recall is 31.1%. While the precision was higher
than the recall on the training data, the reverse is true on the validation data; this is clearly due to the
imbalanced data and the uneven base rates, which explains the especially low precision.
than the recall on the training data, the reverse is true on the validation data; this is clearly due to the
imbalanced data and the uneven base rates, which explains the especially low precision.

SVM
The precision of the SVM was 13% while the recall was 42.2%. While the precision is only slightly
lower than the precision using the random forest, the SVM does a much better job with the recall.
lower than the precision using the random forest, the SVM does a much better job with the recall.

XGBoost
XGBoost is a type of gradient boosting decision trees which improve on each iteration. Therefore,
it unsurprisingly gave us the best performance on the validation data compared to other models
we used. The models allows us to set our own parameters, such as the number of iterations and the
learning rate (eta). We set eta = 0.01; this small value means that the algorithm takes small steps
while optimizing the cost function and therefore results in a cost function which is close to the
global minimum. However, a lower eta implies that the algorithm takes more time and
computational power. We ran the model so 70% of the data is sampled on each iteration and we
ran the model for 5000 iterations.
it unsurprisingly gave us the best performance on the validation data compared to other models
we used. The models allows us to set our own parameters, such as the number of iterations and the
learning rate (eta). We set eta = 0.01; this small value means that the algorithm takes small steps
while optimizing the cost function and therefore results in a cost function which is close to the
global minimum. However, a lower eta implies that the algorithm takes more time and
computational power. We ran the model so 70% of the data is sampled on each iteration and we
ran the model for 5000 iterations.
Upon running this model on the validation data, we got a precision of 42% and because there was
no false negative, the recall was 100%.
no false negative, the recall was 100%.

Conclusion
Considering its efficiency & accuracy of output, we therefore recommend the deployment of the
XGBoost model in predicting whether a user will convert given interest levels in different categories.
Comments
Post a Comment