Correlation analysis - Some caveats
Correlation analysis is an integral part of many EDAs given that it is so easy to execute, visualize and interpret by technical and non-technical audeinces alike. It is a very intuitive metric to compute, and it also happens to be exceedingly useful. An introductory correlation analysis can help us understand what features may be interesting and deserve a closer look, point to potential multicollinearity concerns, and help in identifying opportunities for dimension reduction.
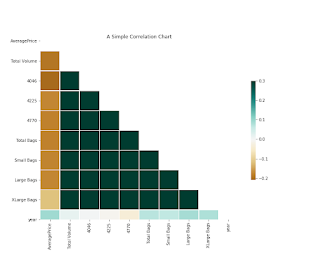
BUT... there is always a but! As with any other metric, correlation comes with its caveats and gotchas which are helpful to keep in mind to get the most out of it - without misusing it. Here are a few pointers to note:


Python functions to run any of these correlations are very simple. To run the correlation for all numeric features of a dataset, simply use the corr function, as in:




1. The most commonly used correlation method, Pearson Correlation, is a measure of the strength of the linear relationship between two variables. The keyword 'linear' is important; just because two variables do not have a high correlation coefficient does not mean that there is no relationship between them. The Pearson correlation coefficient also assumes an approximately Gaussian distribution of the two variables.
Consider the below chart, which plots all integers from -100 to 100 and its squared value - a clear indicator of a relationship.
However, the Pearson correlation coefficient between Y and X is just -0.019. In any EDA exercise, coming across such a small correlation without knowing the underlying data behind it could easily be discarded.
So, what are the alternatives to Pearson's correlation coefficient? You can use Spearman's correlation, which does not assume a linear relationship, not a normal distribution. It does not necessarily indicate a strong relationship in any non-linear relationship but does generally handle non-linearity better than Pearson's coefficient.
For example, consider the below graph of Y = 2/X.
Run a Pearson's correlation test and you'll get a coefficient of 0.13, indicating a weak linear relationship. However, Spearman's correlation picks up the non-linear relationship; the Spearman's correlation coefficient is 0.5.
Another alternative is the Kendall tau correlation. Like Spearman correlation, Kendall tau can be used for ordinal and non-linear data.
which by default computes the Pearson coefficient. You can use the method parameter to return the spearman or kendall correlation instead.
Alternatively, to compute the coefficient between any two arrays, scipy package's stats module has various functions (pearsonr, spearmanr, kendalltau) which return the coefficient along with the p-value of the coefficient being different from zero.
2. The correlation coefficient works well for numeric data. However, using the correlation coefficient to understand relationships between categorical variables can be very misleading. Why? Let's engage in a little exercise.
Let's say we have a dataset on phone brands, the operating system, channel of sales and whether the user is satisfied.
Here is a high-level view of the data:
As we can see, we have predominantly Apple phones in the mix.
Let's take a look at the first five rows of the data.
Now, if we were to do a correlation analysis, we will need to convert the categorical variables to dummy variables for each unique category. We can use pandas's get_dummies function for this.
Now upon computing the correlation and creating a chart, we get:

Looking at the chart, it may seem that Xiaomi customers do not appear to be either strongly satisfied or strongly dissatisfied on average. Let's dig into Xiaomi customers more specifically.
We see that all Xiaomi customers reported that they are not satisfied. So, shouldn't we expect to see a positive correlation between brand_Xiaomi and satisfied_No? In this case, out of 2158 records only 4 have brand as Xiaomi, there are simply not enough to find. The problem is not merely to do with small absolute counts; anytime you have a dataset with highly imbalanced categorical variables, using the correlation coefficient to find interesting relationships may not work well for uncommon categories.
In order to get around this, one possible solution is to use the chi-square test of independence to test whether a pair of categorical variables exhibits dependence. The null hypothesis is that two variables are independent while the alternative hypothesis is that the two variables are dependent.
The first step involves creating a contingency table between the two variables and then computing the chi-square value based on the contingency table. You can use this Python UDF which incorporates both steps for as many categorical columns of a dataframe you like. This function will output the p-value of the chi-square test of each of your mentioned variables with every categorical variable in the dataframe.
Of course, running the chi-square test for dependence in our current case, with 4 Xiaomi customers, will return a very high p-value due to the small sample size. However, if you had a larger dataset with more Xiaomi customers but with the same proportion of Xiaomi customers in the entire data, your p-value would fall even though running a correlation with the larger dataset will return the same output. As with correlation itself, the chi-square test returns a higher likelihood of false negatives for small samples and power of a test can be improved by increasing the size of the sample.
3. Finally - the well-known caveat - correlation does not imply causation - is always worth keeping in mind. A strong correlation between two variables certainly makes them interesting to study further but in no way implies a causation.
I hope this short article provided some insights into how to best use correlation analysis as a tool for your EDA - and the alternatives that are available when correlation is not a good fit.
Comments
Post a Comment